
Accessibilité numérique : de quoi parlons-nous? L’accessibilité numérique, c’est rendre les produits numériques (sites, applications mais aussi data visualisations) accessibles aux personnes en situation...

Améliorer l’écoute de son client grâce au NLP
Le monde de l’entreprise connaît une multiplication des points de contact avec les clients. Chacun peut rédiger un avis, un post sur un réseau social, un ticket ou un email. Cette source d’information est extrêmement riche puisqu’elle contient les ressentis et les questionnements des clients. Cependant, ces données sont rarement suffisamment exploitées alors qu’elles pourraient permettre de mieux comprendre les points d’insatisfaction ou de questionnement des clients.
Le traitement automatique du langage dit naturel, appelé aussi Natural Language Processing (NLP) en anglais, est une technologie permettant à des machines d’analyser le langage humain grâce à l’intelligence artificielle (IA). L’ordinateur peut alors comprendre et synthétiser les retours clients.
Il existe de nombreuses techniques autour du NLP, telles que :
Nous ne nous focaliserons ici que sur les techniques de traitement de textes qui nous permettent de remplir notre objectif d’écoute des clients : l’analyse de sentiment, la détection automatique de thèmes, appelée topic modeling, ou encore la classification de messages dans des thèmes.

L’analyse de sentiment permet de connaître la satisfaction des clients et ainsi guider les stratégies commerciales. Mettre en place un monitoring de la satisfaction permet alors de la suivre dans le temps et d’en suivre les tendances :
Cette méthode peut aussi être utilisée pour segmenter la base des utilisateurs en plusieurs catégories et ainsi avoir une communication adaptée à chaque groupe ou prioriser les réponses à donner en urgence. Un message ayant un sentiment négatif peut provenir d’un client particulièrement insatisfait auquel il sera préférable de répondre rapidement.
Enfin, il peut aussi servir d’indicateur dans les prédictions, par exemple, avec le lancement d’un nouveau produit ou d’une nouvelle campagne marketing.
Du côté pratique, quel que soit le cas d’usage, les algorithmes de Data Science ne savent pas manipuler du texte brut. C’est pourquoi une étape de préparation des données est nécessaire. Le premier objectif de cette préparation est de réduire le nombre de mots pour ne conserver que ceux donnant son sens au message. Il est possible d’effectuer les étapes suivantes :
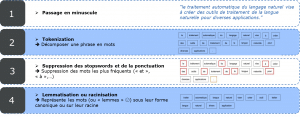
Ces étapes sont courantes mais pas systématiques ! Tout dépend de votre objectif. Par exemple, pour détecter des spams, l’utilisation des majuscules donnera un signal important. Ensuite, habituellement, chaque texte est transformé en des vecteurs de mots qui mènent à créer une matrice document-terme qui sera l’entrée de l’analyse. Cela facilite l’usage de certains algorithmes qui ne prennent en entrée que des nombres.
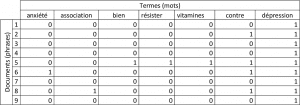
Côté méthodologie, plusieurs approches s’offrent à vous :
Toutes ces méthodes conduisent au même résultat qui donne pour chaque message un score de satisfaction permettant de quantifier la satisfaction ou l’insatisfaction du client.

=> Negatif à 95% ! Message pour lequel il faut répondre rapidement !
La deuxième fonctionnalité principale du NLP est l’extraction de thèmes plus communément appelée topic modeling. Le topic modeling peut s’appliquer à toute forme de texte : mails, tickets, feedbacks, etc. pour avoir une vision globale des préoccupations des clients.
Les principaux modèles de topic modeling sont non-supervisés. C’est-à-dire qu’ils n’apprennent pas à lier des messages à un thème donné, ils découvrent eux-mêmes les thèmes.
Mais avant d’être analysés, les messages doivent passer par la même préparation que pour l’analyse de sentiment. Ensuite, il existe, là encore, plusieurs méthodologies possibles :

Ces 3 approches demandent de donner en paramètre le nombre de thèmes. Il existe des critères statistiques pour donner une indication sur le nombre de thèmes optimal mais il reste nécessaire, pour choisir sa méthodologie ou son nombre de thèmes, de s’assurer de la pertinence de l’interprétation des topics.
Les modèles vous fournissent le numéro du thème auquel le message est associé, voire même l’importance relative de chaque thème pour le message. Quoiqu’il en soit, le thème ne sera qu’un listing de mots auquel vous devrez associer vous-mêmes un nom.

Il est également possible d’associer des messages à des thèmes connus si vous disposez d’anciens messages associés à ces thèmes. Des modèles de Machine Learning permettent d’apprendre le lien entre leurs contenus et les thèmes.
Cette méthode est par exemple utilisée pour classer les mails dans les spams dans les systèmes de messagerie ou plus largement, elle peut être utilisée pour classer des mails et les rediriger vers le service en charge de sa réponse.
Pour effectuer cette tâche, plusieurs modèles existent et notamment l’algorithme des k plus proches voisins (kNN), les SVM, la régression logistique ou les réseaux de neurones.
Les méthodes vues dans cet article peuvent être combinées entre elles ou avec d’autres pour extraire d’autres informations.
Par exemple, le topic modeling, utilisé en parallèle d’une analyse de sentiment, permet de mettre en lumière les sujets de mécontentement des utilisateurs. Il permet de savoir si les clients sont satisfaits ou non d’un service en particulier. Il indique ainsi les services à améliorer en priorité.
Le NLP peut aussi être élargi aux données de centres d’appels ou d’assistants personnels. Des méthodes de text-to-speech permettent de transcrire les données vocales en texte sur lequel toutes les méthodes vues précédemment peuvent s’appliquer.
Les données textuelles, ou plus généralement de langage, sont omniprésentes et souvent sous-exploitées bien qu’elles contiennent des informations clés. Utiliser des méthodes de NLP comme l’analyse de sentiment, le topic modeling et la classification permet d’être plus à l’écoute de vos clients et ainsi améliorer la prise de décisions stratégiques. La diversification des types de données, l’augmentation du volume de données (sous forme de texte ou de son) vont s’accélérer dans les prochaines années. C’est donc une source d’information capitale pour la relation client et la stratégie de l’entreprise.
AVISIA se tient donc à votre disposition pour vous aider à réaliser ces projets !




 (1600 x 760 px) (1920 x 1080 px)-2")













Data contact


