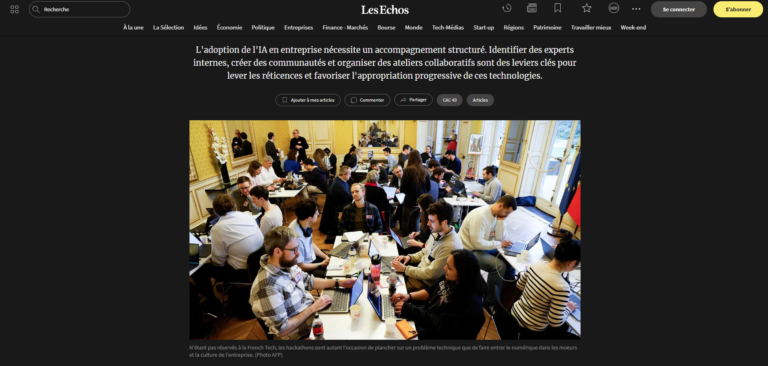
Avec l’augmentation des données mises à disposition, de nombreux risques d’erreur peuvent émerger dans un projet de data scienceQu'est-ce que la Data Science ? La Data Science, ou science des données, est une discipline interdisciplinaire qui utilise des méthodes scientifiques, des processus, des algorithmes et des systèmes pour extraire des connaissances et des insights à partir de données, qu'elles soient structurées... More. Par conséquent, le data scientist peut compter sur le nettoyage des données (ou en anglais data cleaning) pour optimiser les processus de gestion de données. Cette étape est importante puisqu’elle renforce l’intégrité et la pertinence des données en réduisant les incohérences, en évitant les erreurs et en permettant de prendre des décisions mieux avisées et plus précises. Un des buts ici, va être de détecter les anomalies car celles-ci constituent un réel problème pour le data scientist, notamment à cause du biais qu’elles peuvent apporter sur le modèle et des impacts qui en découlent. Ces anomalies peuvent être, par exemple, attribuées à des erreurs d’acquisition de données ou encore à des individus ayant des comportements inhabituels.
Afin de détecter ces anomalies, qu’elles soit simples ou complexes, il est possible d’utiliser des méthodes récentes basées sur de l’Intelligence Artificielle (I.A.) et qui commencent à se démocratiser peu importe le domaine d’activité. Ces méthodes sont nombreuses, complexes et ont des objectifs différents. Il est donc important de bien choisir la méthode en fonction du besoin identifié par le data scientist et/ou par le métier. Nous allons détailler dans cet article plusieurs axes permettant d’articuler la réflexion sur le choix de la bonne méthode de détection d’anomalie, à savoir : cadrer ce que nous entendons par une anomalie, identifier la bonne méthode pour répondre au problème et partager quelques pratiques courantes relatives à la détection d’anomalies.
Cadrer ce qu’est une anomalie
Nous employons bien souvent le terme « d’anomalie » sans réellement comprendre ni prendre en considération ce qu’il évoque dans son entièreté. De manière globale, nous parlons d’anomalie, ou encore « d’outlier » en anglais, lorsqu’une observation contraste avec les autres valeurs. Cette valeur est dite « distante » des autres observations effectuées sur le même phénomène. Par ailleurs, il existe un certain nombre de critères, peu connus et maîtrisés, qui permettent de distinguer les différentes anomalies.
Faire la distinction entre valeur aberrante et valeur atypique
Tout d’abord, il est à noter que l’on peut splitter les anomalies en deux catégories. Nous parlons de « donnée aberrante » s’il s’agit d’une valeur fausse et qui doit donc être éliminée, et de « donnée atypique » dans le cas où la valeur se distingue des autres mais sans être fausse pour autant. Ces deux termes sont souvent confondus et, de ce fait, mal employés. Par exemple, si une personne fait 3 mètres, il s’agira d’une mesure impossible, nous parlons donc de valeur aberrante. En revanche, si elle fait 2m il s’agira seulement d’une taille peu fréquente, et donc d’une valeur atypique.
Définir les trois types d’anomalies différents
Il existe trois différents types d’anomalies, qu’elles soient aberrantes ou atypiques, qu’il est important de différencier afin de trouver la stratégie adaptée au contexte : les anomalies ponctuelles, les anomalies contextuelles et enfin les anomalies collectives.
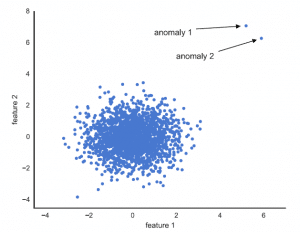
Figure 1 : Anomalies ponctuelles
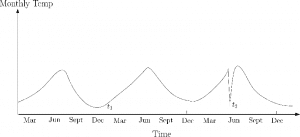
Figure 2 : Anomalies contextuelles
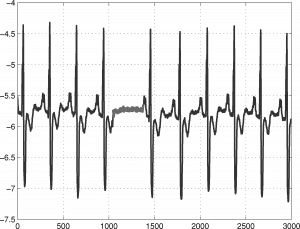
Figure 3 : Anomalies collectives
Les anomalies ponctuelles (autrement appelées anomalies globales) correspondent aux points qui diffèrent des autres selon une métrique donnée (distance par exemple). Dans la figure 1 ci-dessus, par exemple, nous remarquons deux anomalies ponctuelles : les points sont très distants du reste des données. Dans le secteur bancaire par exemple, une anomalie ponctuelle pourrait correspondre à une personne qui a des revenus particulièrement élevés.
Les anomalies contextuelles se présentent lorsque les valeurs peuvent être normales dans un contexte, mais anormales dans un autre. Par exemple, supposons que nous nous situons dans le contexte où tous les magasins ont dû fermer du jour au lendemain en raison de la COVID, ainsi le nombre de ventes de produits passe soudainement à 0 alors qu’il s’élève habituellement à 1000. Tenant compte du contexte, il ne s’agit donc pas d’une anomalie, elle s’explique par la fermeture du magasin. Dans un contexte de données météorologiques, pour illustrer un autre exemple, une température de 0 degré pendant l’été est une anomalie, puisque l’on s’attend à avoir environ 25 degrés, alors que pendant l’hiver, cela peut être normal. La figure 2 permet d’illustrer ce type d’anomalie car nous constatons que la température t2 aurait été « normale » au mois de décembre (« dec » sur le graphique) mais elle ne l’est pas pour le mois de juin (« jun » sur le graphique).
Enfin, les anomalies collectives qualifient un sous-ensemble de données qui s’éloigne par rapport au reste de l’ensemble de données. Prise individuellement, une observation pourrait ne pas être considérée comme anomalie tandis que le groupe auquel appartient cette instance indique une anomalie, comme l’illustre la figure 3 pour les individus ayant une valeur, sur l’axe des abscisses, comprise entre 1000 et 15000. Si l’on se place dans le monde de la banque par exemple, il ne semble pas anormal qu’une personne demande un octroi de crédit. Cependant si tous les clients demandent un octroi de crédit le même jour, il semblerait effectivement qu’il y ait une anomalie dans les données.
Distinguer les deux méthodes de détection d’anomalies
En pratique, il existe une distinction entre deux méthodes : la détection d’anomalies et la détection des nouveautés.
La détection initiale d’anomalies représente les points qui s’écartent significativement des autres au sein d’un jeu de données sur lequel le programme apprend. Il est essentiel d’identifier ces instances au préalable afin qu’elles n’impactent pas la qualité du modèle.
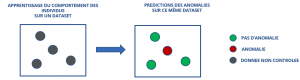
Détection initiale des anomalies
La détection des nouveautés correspond à la détection d’un positionnement anormal d’un nouvel individu par rapport à un jeu de données initial d’apprentissage, qui lui ne contient aucune ou un nombre connu d’anomalies. Autrement dit, nous cherchons donc à déterminer si ce nouvel individu est proche des individus du jeu de données d’apprentissage ou s’il s’en écarte significativement.

Détection des nouveautés
Une bonne pratique pour faire de la détection des nouveautés, est de faire au préalable l’étape de détection initiale des anomalies pour avoir un jeu de données initial propre ou de s’assurer avec le métier que le jeu de données initial est sans anomalies.
Ainsi, il est important de distinguer les différents types et catégories d’anomalies pour cerner le contexte dans lequel nous nous situons dans le but d’assurer une bonne compréhension de l’enjeu. Il s’agit ensuite de déterminer la solution qui permettra de détecter au mieux les anomalies.
Identifier la bonne méthode pour répondre au problème
La multitude de structures de données et de domaines d’applications qui existent, conduit à une variété toute aussi importante de méthodes de détection d’anomalies. Cependant, déterminer celle qui sera adéquate au problème peut rapidement se transformer en un réel casse-tête.
Paramètres à prendre en compte lors du choix de la méthode
Dans un premier temps, le data scientist peut se trouver limité par le temps qu’il peut accorder à la détection des anomalies. En effet, différentes étapes sont nécessaires pour mener à bien un projet data et ceci souvent dans un temps imparti. Il est donc important de trouver un bon compromis entre la qualité et le temps alloué à la détection d’anomalies dans la phase de « data cleaning ». Pour se faire, il est donc recommandé d’itérer, dans un premier temps, en choisissant une méthode simple telle qu’un Boxplot ou une régression linéaire. Ces méthodes permettent généralement d’apporter une assez bonne détection des outliers majeurs et ont l’avantage d’être faciles et rapides à implémenter. Elles permettront par ailleurs, de comparer les résultats obtenus avec ceux de modèles plus complexes et ainsi d’apporter une mesure de fiabilité supplémentaire aux modèles moins facilement interprétables.
Ensuite, il est important de bien analyser la structure des données pour déterminer la méthode qui sera la plus pertinente. Plusieurs critères relatifs aux données permettent de nous orienter vers la bonne méthode : si les données sont structurées ou non, s’il s’agit de données en grandes dimensions, le nombre de variables à utiliser dans le modèle ou encore le type de ces variables (numériques, catégoriques, etc …).
Par ailleurs certains critères, relevant de la mise en œuvre, sont à prendre en considération : la méthode requiert elle une implication humaine (méthode supervisée, non supervisée, semi-supervisée) ? Les données sont-elles censées suivre une loi de distribution déterminée (méthode paramétriques, non-paramétriques, semi-paramétriques) ?
Enfin, comparer les différentes méthodes en se basant sur des critères de performances, tels que la précision, la rapidité ou encore la robustesse de cette détection permettront de finaliser le choix concernant la stratégie à adapter.
Vision étendue sur les différentes méthodes de détection d’anomalies
Il y a une multitude de techniques de détection d’anomalies qui se différencient selon les techniques utilisées, telles que : les statistiques, le clustering, les plus proches voisins, ou encore des méthodes d’arborescence pour parvenir à détecter ces individus anormaux. Chacune d’entre elles s’appuie sur les deux caractéristiques principales des anomalies : la rareté et la singularité.
Les techniques statistiques se basent sur les données pour construire un modèle : les données qui s’éloignent de ce modèle sont alors considérées comme anormales. Il existe deux approches statistiques : l’approche non paramétrique qui inclus des méthodes simples telles que le boxplot ou l’histogramme, et l’approche paramétrique qui est plus complexe. Cette dernière, autrement appelée approche probabiliste, nécessite la connaissance a priori de la distribution des données (si elles suivent une loi gaussienne, etc ..) et permet de fournir un intervalle de confiance.
Les techniques qui se basent sur les plus proches voisins comparent les instances (individus) par rapport à celles de leur plus proches voisins. Ces méthodes nécessitent donc un calcul de distance entre toutes les instances au préalable et sont, de ce fait, souvent coûteuse en terme de temps d’exécution.
Les techniques basées sur le clustering divisent quant à elles le jeu de données en différents groupes (ou « clusters »). Ceci de sorte à avoir les données les plus similaires possible à l’intérieur des clusters et les plus différentes possibles entre les différents clusters. Là encore nous pouvons séparer cette technique en deux : l’approche selon la distance pour laquelle le cluster le plus éloigné comprend les données dites anormales et l’approche qui utilise la densité en désignant comme anomalies les données comprises dans le cluster avec le moins de données.
Bien d’autres techniques existent comme celles basées sur l’arborescence, sur les machines à vecteurs de support, les réseaux de neurones, etc ..
Ci-dessous une représentation, bien que non exhaustive, assez complète sur les différents modèles algorithmes qui existent.
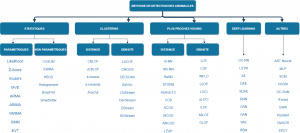
Ainsi, un très grand nombre de méthodes existent pour assurer la détection des anomalies. Nous nous focaliserons, dans cet article, sur une petite partie d’entre elles parmi les plus en vues d’après les papiers de recherche : L’isolation Forest (IForest) et le Local Outlier Factor (LOF).
Utiliser des méthodes récentes de détection automatique d’anomalies
Pour s’assurer d’une détection plus fine des anomalies, il est préférable d’utiliser des méthodes basées sur le Machine Learning et non des techniques basées sur des statistiques simples comme le Boxplot. Ces méthodes plus complexes peuvent utiliser davantage de variables (ou ‘features’) dans leur modèle et ainsi comprendre, les relations sous-jacentes qui existent entre ces dernières : l’analyse sera donc plus « intelligente ». Par exemple, supposons que nous sommes dans le contexte des produits cosmétiques, avec un prix des rouges à lèvres qui se situe pour la majorité autour de 12 euros. Si un rouge à lèvre a, quant à lui, un prix de 50 euros, une méthode qui prendrait en compte seulement la variable prix le détectera comme anomalie. Cependant cette différence de prix peut finalement s’expliquer par d’autres variables, telle que la marque de ce rouge à lèvre, il est donc judicieux de prendre en compte simultanément toutes les variables contribuant à l’explication du prix.
Pour détecter ces différentes anomalies grâce à des méthodes basées sur le Machine Learning, nous pouvons utiliser :
La forêt d’isolation ( » Isolation Forest « ) est une méthode de détection automatique des anomalies développée en 2008 et dont le principe est de construire un ensemble d’arbres d’isolation pour séparer les individus. Chaque arbre d’isolation est construit sur un échantillon tiré aléatoirement, ce qui vaut la particularité à l’Isolation Forest ne pas être obligé d’utiliser toutes les données pour construire l’ensembles des arbres. Le principe d’un arbre d’isolation est de diviser les données de manière itérative en commençant à la racine de l’arbre (nœud initial de l’arbre comportant l’intégralité des données). Pour se faire, à chaque nœud nous sélectionnons aléatoirement une variable et un seuil, qui permettent de séparer les données en deux sous-échantillons distincts. Le postulat est qu’un individu atypique se retrouvera plus rapidement isolé (seul dans son nœud) qu’un individu standard. Ceci se base sur la supposition qu’une anomalie est dotée de variables avec une valeur très différente des individus « standards ».
L’Isolation Forest est une des méthodes les plus récentes et, témoignant souvent des meilleures performances même en grande dimension, il s’agit d’une des méthodes les plus utilisées dans la détection d’anomalies. Cette méthode ensembliste à également l’avantage de consommer peu de CPU, de temps et de mémoire. Cette méthode reste cependant pas facile à interpréter et est moins adaptée aux données catégorielles.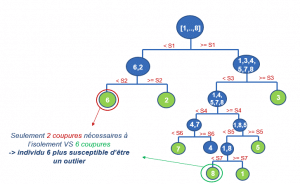 N’hésitez pas à consulter les articles suivants pour plus de détail sur cette méthode :
N’hésitez pas à consulter les articles suivants pour plus de détail sur cette méthode :
- https://towardsdatascience.com/isolation-forest-the-anomaly-detection-algorithm-any-data-scientist-should-know-1a99622eec2d
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
Le facteur local d’anomalie ( » Local Outlier Factor « ), est une technique développée en 2000 et dont l’idée principale est de comparer la densité locale d’une observation avec celle de ses voisins les plus proches. Si elle est inférieure à celle de ses voisins, alors l’individu se retrouve dans une région peu dense et sera de ce fait plus susceptible d’être une anomalie. Une valeur de score d’anomalie, appelée la » valeur de Local Outlier Factor » permet de définir ce critère de densité. Ce score est effectivement calculé en opposant la valeur de densité de l’individu avec la densité de ses plus proches voisins.
L’approche locale du LOF, permet d’avoir une méthode applicable même si les données sont organisées en clusters. Cette méthode a par ailleurs l’avantage de tenir compte de la densité des points et reste performante et généralisable sur tous types de données, y compris les données multimodales. Néanmoins, la valeur du LOF est difficile à interpréter et cette méthode perd en efficacité s’il y a trop de variables. Cette méthode peut être également longue au vu de la complexité des calculs a effectuer.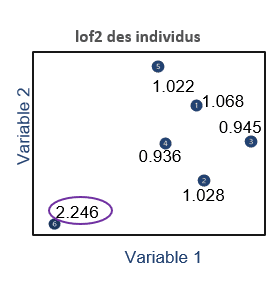
N’hésitez pas à consulter les articles suivants pour plus de détail sur cette méthode :
- https://towardsdatascience.com/local-outlier-factor-lof-algorithm-for-outlier-identification-8efb887d9843
- https://scikit-learn.org/stable/auto_examples/neighbors/plot_lof_outlier_detection.html
Il n’y a pas de méthode « miracle », chacune à ses avantages et ses inconvénients, et choisir la méthode la plus adéquate dépend souvent du contexte (nombre de données, nombre et types de variables, types d’anomalies recherchées ..). Il est recommandé d’en tester et d’en comparer plusieurs afin de choisir celle qui conviendra le mieux, ou encore de combiner les résultats obtenus par différentes méthodes.
Utiliser ces méthodes pour détecter les anomalies demande une certaine expertise et certaines pratiques sont utiles, voire indispensables, pour assurer une mise en œuvre des plus optimale.
Quelques bonnes pratiques courantes relatives à la détection d’anomalies
La mise en œuvre des méthodes basées sur le Machine Learning reste assez complexe et il est donc primordial de suivre des bonnes pratiques et de choisir les bons outils pour avoir une détection d’anomalies la plus fiable possible, tels qu’exposés dans les parties suivantes. Nous découvrirons également dans quelle mesure ces méthodes peuvent être utilisées à d’autres fins que la détection d’anomalies pure.
Quelques bonnes pratiques pour bien détecter les anomalies
Tout d’abord, la détection des anomalies doit être anticipée à travers l’étape de pré-Processing. Pour ce faire, il est recommandé de commencer par faire des statistiques descriptives afin d’avoir une première idée sur les potentielles anomalies, ceci à travers une estimation de la quantité de ces dernières et des critères qui faciliteront leur repérage. A posteriori, cela permettra de comparer avec les résultats que l’on peut avoir à travers les modèles de Machine Learning et ainsi de se conforter ou non dans l’utilisation de ces méthodes plus complexes. De plus, il est important d’analyser les corrélations qui existent entre les variables. Cette étape va permettre d’assurer une sélection pertinente des variables à injecter dans le modèle de détection d’anomalies ainsi que permettre de limiter la complexité du modèle en limitant le nombre de variables. Cette première étude permettra également de recenser quelques anomalies afin de les présenter aux personnes métiers qui pourront, grâce à leur expertise, apporter des explications complémentaires sur ces individus repérés.
Le second élément clé pour mener à bien la détection d’anomalies est de bien comprendre le fonctionnement de votre modèle. Pour cela, il est possible d’utiliser des méthodes d’interprétabilité pour analyser la manière dont les anomalies ont été trouvées et s’assurer que c’est bien en accord avec l’objectif. Cela permet au data scientist d’itérer le modèle et de l’ajuster au besoin.
Enfin il ne faut pas négliger l’importance de la supervision des anomalies détectées. En effet, il peut être dangereux de supprimer les anomalies détecter sans mettre aucune vérification sur celles-ci. Pour ce faire, il est plus que conseillé de mettre des check sur les anomalies détectées afin de les surveiller et donc de ne pas éliminer des informations importantes. Ces checks peuvent se traduire par un suivi de la quantité des anomalies détectées de manière globale ou encore par variable (exemple : la rareté des individus ayant pour valeur année « 2022 », s’expliquant par l’entrée dans une nouvelle année).
Choisir l’outil adapté
Une grande majorité de ces modèles sont implémentables sur de nombreux logiciels, tels que SAS, GCP, python ou encore R. De nombreux packages sklearn sous Python sont par ailleurs disponibles et permettent une mise en œuvre très facile, ceci grâce à la documentation disponible très détaillée.
Dataiku DSS est également un outil très utile pour la détection des anomalies puisqu’il est possible d’appliquer ces méthodes techniquement avec du code mais également de manière automatique avec du clic – bouton (utile si vous ne savez coder).
Suivre le modèle de détection en production
Au delà d’améliorer le nettoyage des données, la détection des nouveautés permet de suivre la qualité de représentation des nouveaux individus qui vont servir dans le projet data science en production. Cette étape est importante car elle permet de suivre si les nouvelles données sont similaires aux données d’apprentissage ou autrement dit de s’assurer que le modèle s’adapte bien en cas de variation de la distribution des données. Attention, si les nouvelles données sont nombreuses et varient de manière significative alors le nombre d’anomalies va considérablement augmentées, il sera donc utile de relancer l’apprentissage du modèle de détection d’anomalies.
Bien que ces méthodes aient fait leur preuve, il reste important de les manier avec recul et vigilance et de choisir le bon outil pour les implémenter.
Perspectives
Nous avons décrit les principaux axes de réflexion sur le choix de la bonne méthode de détection d’anomalie par le data scientist afin que le projet de data science soit précis et fiable. Il existe de nombreuses méthodes, comme vu précédemment dans l’article, qui possèdent chacune leurs avantages et inconvénients en termes de complexité, simplicité et performance. Il est nécessaire de comparer ces méthodes, du plus simple au plus complexe, afin d’identifier la méthode répondant au besoin le plus rapidement et efficacement.
Si vous avez besoin d’être accompagnés sur ce type de sujet, nous pouvons mettre à profit nos expertises, validées par de nombreux retours d’expériences chez nos clients, pour vous aider à les implémenter.

Léna COIC & Nicolas BETIN.