
Accessibilité numérique : de quoi parlons-nous? L’accessibilité numérique, c’est rendre les produits numériques (sites, applications mais aussi data visualisations) accessibles aux personnes en situation...

Les méthodes pour interpréter des modèles de machine learning complexes
Actuellement, dans l’univers de la data science et plus précisément du machine learning, quand une entreprise souhaite employer des algorithmes supervisés, c’est-à-dire pour prédire l’appétence ou l’attrition de ses clients, la souscription ou le remboursement d’un produit bancaire, etc., les algorithmes classiques tels que les arbres de décision ou la régression logistique ne suffisent plus à atteindre les niveaux de précision exigés. Des nouvelles méthodes comme XGBoost [1] atteignent des niveaux de performance bien plus élevés que ces méthodes ; sur une comparaison avec 165 jeux de données [2], la régression logistique est plus performante dans seulement 5% et les arbres dans 2% des cas.
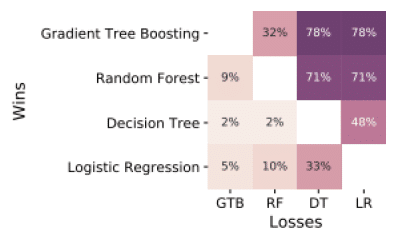
Comparaison d’algorithmes sur 165 jeux de données. Source [2]
Ces nouvelles méthodes sont plus efficaces pour plusieurs raisons :
Le trade-off avec ces nouveaux modèles est qu’en gagnant en performance, nous perdons en interprétabilité.
L’interprétabilité d’un modèle, que nous pouvons définir comme la capacité à comprendre les raisons d’une décision d’un modèle, est nécessaire pour plusieurs raisons :
Les différentes méthodes d’interprétabilité peuvent être définies selon 3 axes :
Voici un tableau récapitulant les méthodes les plus importantes, classées selon les 3 axes :
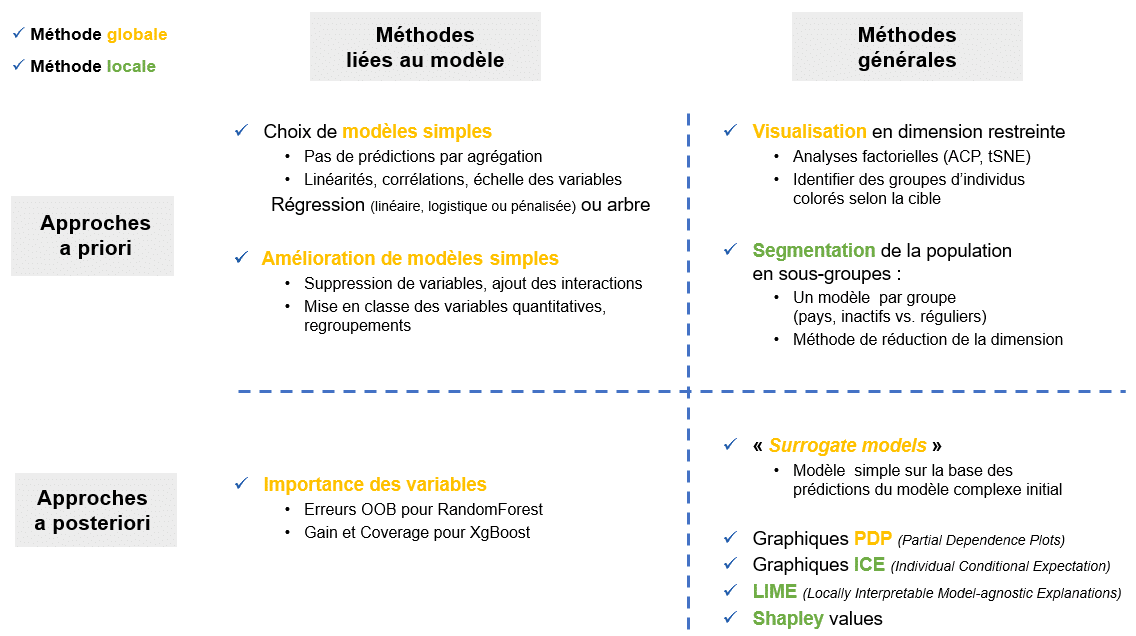
Descriptif de nombreuses méthodes selon 3 axes
Présentons maintenant 3 méthodes que nous pensons à Avisia comme étant les plus prometteuses.
Ces deux graphiques permettent d’inspecter la relation entre une variable explicative (voire deux) et le phénomène à expliquer pour lequel nous calculons des prédictions. Le procédé pour ICE (Individual Conditional Expectations [3]) est le suivant :
Le graphique PDP (Partial Dependance Plot [4]) n’est que la moyenne des courbes individuelles pour toutes les valeurs de la variable.
Voici un exemple avec les données et le modèle XGBoost dont la description des variables et les codes de création sont en annexe :

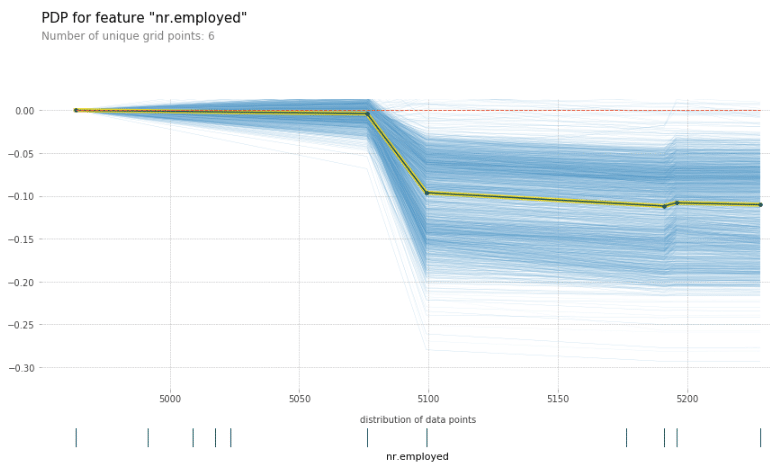
Code et graphique ICE/PDP pour la variable nr.employed
Le fait d’analyser le lien entre variable explicative et cible avant la création du modèle est moins robuste que les méthodes PDP & ICE, car nous ne prendrions pas en compte les effets d’interaction entre toutes les variables explicatives. Pour la variable nr.employed utilisée, nous voyons que les valeurs plus faibles ont un impact similaire, alors que des valeurs supérieures à 5100 ont un impact négatif. La relation semble similaire pour tous les individus. Note : la ligne jaune et noire correspond au PDP.
Les valeurs de Shapley empruntent à la théorie des jeux et représentent, pour un individu, la contribution de la valeur d’une variable à la prédiction de cet individu. La contribution de toutes les variables représente la différence entre la prédiction individuelle et la prédiction moyenne (tous les individus).


Code et graphique Shapley pour un individu
Le graphique nous montre que pour cet individu, la prédiction est bien inférieure à la prédiction moyenne. Cela est surtout dû aux variables emp.var.rate et duration, qui tirent la prédiction vers 0. L’influence de la variable nr.employed est cohérente avec le graphique PDP ci-dessus.
Note : la probabilité prédite de 0,2% s’obtient en utilisant la fonction sigmoïde au point -6,23.
La méthode permet aussi, entre autres, d’avoir l’importance des variables dans le modèle, de manière fiable :
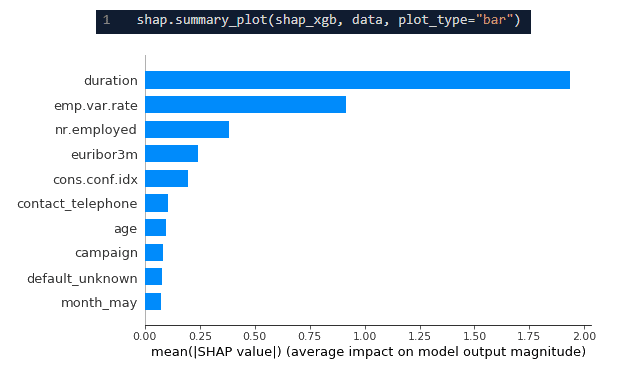
Code et graphique d’importance des variables par les valeurs de Shapley
La méthode LIME [5] consiste à expliquer la prédiction d’un individu par un modèle simple (régression L1 pondérée), et ce uniquement pour les individus dans son voisinage (qui lui sont semblables). En effet, si un modèle peut être globalement complexe, il sera localement plus simple.
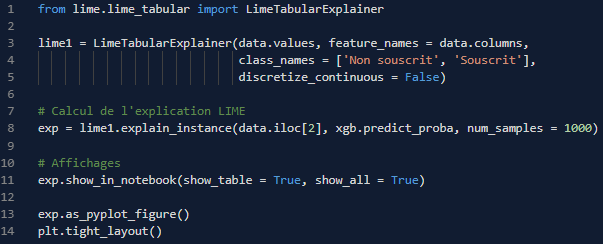
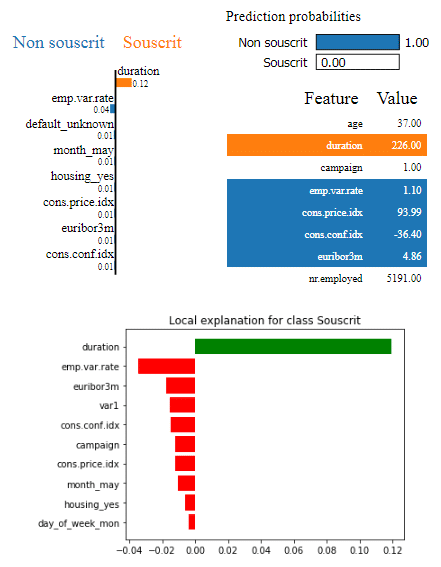
Code et graphique LIME pour un individu
Différents graphiques sont possibles en fonction des affinités ! Dans tous les cas, pour cet individu (le même que pour Shapley), nous voyons que, malgré sa probabilité proche de 0, la variable duration a eu le plus d’importance et a eu tendance à augmenter la probabilité finale. Cette analyse est en contradiction avec la méthode Shapley ; c’est dû à trois raisons, qui peuvent faire la faiblesse de LIME :
![]()
![]()
Les exigences réglementaires et d’utilisation en contexte d’entreprise demandent de plus en plus d’avoir des modèles à la fois simples et performants. Le fait de pouvoir interpréter facilement et efficacement des modèles complexes en facilite l’emploi et doit être un outil dans la panoplie du data scientist moderne. Grâce aux méthodes présentées dans cet article, l’interprétabilité et la performance deviennent accessibles. La méthode la plus utile est la valeur Shapley, qui permet de déterminer à la fois ce qui joue pour la prédiction d’un individu (sens et importance), de tous les individus (importance des variables), et plus spécifiquement pour une variable ou l’interaction de deux variables. La méthode PDP peut en être complémentaire.
Notons qu’à part la méthode LIME, l’interprétation de données textuelles et d’images donnent lieu à des méthodes plus complexes, différentes et encore en recherche. Stay tuned!
Le jeu de données est une légère modification de celui disponible sur l’archive UCI ML [6]. Le but est de prédire si des clients d’une banque vont effectuer un dépôt à terme après des contacts de marketing direct. Les créateurs de ces données indiquent que la variable duration est fortement explicative du dépôt.
Voici le code utilité pour le traitement des données et le modèle XGBoost :
# Import
import pandas as pd
data = pd.read_csv('bank-additional-full-atelier.csv')
# Pretraitement
y = data['y']
del data['y']
# One hot encoding
data_car = data.select_dtypes('object')
data_num = [x for x in data if x not in data_car]
data_num = data[data_num]
data_dummies = pd.get_dummies(data_car, drop_first = True
data = pd.concat([data_num, data_dummies], axis = 1)
# Modélisation XGBoost
import xgboost
xgb = xgboost.XGBClassifier(learning_rate = 0.03, n_estimators = 500, max_depth = 4, objective = 'binary:logistic')
xgb.fit(data.valyes, y)
[1] Chen T., Guestrin C. (2016). https://arxiv.org/abs/1603.02754v1
[2] Olson R. S., La Cava W., Mustahsan Z., Varik A., and Jason H. Moore (2018). Data-driven advice for applying machine learning to bioinformatics problems, https://psb.stanford.edu/psb-online/proceedings/psb18/olson.pdf
[3] Goldstein A., Kapelner A., Bleich J., Pitkin E. (2013). Peeking Inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation, https://arxiv.org/abs/1309.6392
[4] Friedman J. H. (2001). Greedy function approximation: A gradient boosting machine, https://statweb.stanford.edu/~jhf/ftp/trebst.pdf
[5] Ribeiro M. T., Singh S., Guestrin C. (2016). Why should I trust you?: Explaining the predictions of any classifier, https://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdf
[6] Moro S., Cortez P., Rita P. (2014). A Data-Driven Approach to Predict the Success of Bank Telemarketing https://archive.ics.uci.edu/ml/datasets/bank+marketing




 (1600 x 760 px) (1920 x 1080 px)-2")














Data contact


