
Accessibilité numérique : de quoi parlons-nous? L’accessibilité numérique, c’est rendre les produits numériques (sites, applications mais aussi data visualisations) accessibles aux personnes en situation...

Créer un modèle Next Best Action et réduire le churn
Personnaliser la relation qu’une entreprise met en oeuvre pour chacun de ses clients est un facteur clé de la fidélisation de long-terme et est vitale pour la stratégie marketing d’une entreprise, et donc sa croissance. Cela est d’autant plus important pour les entreprises où l’attrition est un problème majeur, notamment à cause de la complexité ou du coût d’acquisition de nouveaux clients. C’est le cas par exemple des télécoms, des assurances.
Afin de personnaliser cette relation client, il est possible de déterminer, pour chaque client, quelle est la prochaine meilleure étape à réaliser (Next Best Action, abrégé NBA). Cependant, l’évaluation de la pertinence de l’approche est complexe, car l’entreprise ne sait pas encore quelles prochaines actions seraient pertinentes vu qu’elle ne les a pas encore mises en place. Nous allons détailler dans cet article la construction d’un modèle NBA et l’évaluation de sa performance hors production.
Les modèles NBA peuvent permettre de personnaliser tout un type d’actions, comme par exemple la personnalisation du contenu (comme Netflix), la solution à apporter dans un centre de relation client, l’envoi d’offres promotionnelles ciblées, etc.
Prenons le cas d’une entreprise qui cherche à prévenir l’attrition de ses clients, et qui propose un service (par abonnement ou non) avec lequel ses clients interagissent souvent. L’attrition sera donc ici définie comme le fait d’annuler un abonnement ou de fortement décroître l’usage de ces services (chute de X% sur le dernier mois par rapport au mois précédent, par exemple). Pour les clients prédits comme étant à fort risque de churn (= attrition), nous souhaitons mettre en place des actions marketing et commerciales afin de réduire ce risque : envoi de coupons et réductions, appel sortant du service client pour identifier les insatisfactions du client, etc.
Cette entreprise, comme elle est data-driven (et donc accompagnée par AVISIA 👩💻), enregistre l’historique des interactions entre le client et l’entreprise (usage du service, contacts avec le service client, navigation sur le site Internet de l’entreprise, …), mais aussi les différentes offres marketing qui ont été mises en place pour ce client. Pour complexifier la tâche, supposons que nous ne connaissons pas la logique du ciblage des différentes offres marketing mises en place : l’offre a été envoyée par un découpage géographique, selon une segmentation comportementale, avec une segmentation démographique (genre, âge, revenus, …) ou autre.
L’objectif est donc de créer un modèle qui détermine la NBA, c’est-à-dire choisir la prochaine étape selon le profil du client dans sa relation avec l’entreprise. Et, par la suite, d’évaluer la performance de ce modèle avec uniquement des données passées, afin de voir s’il peut être déployé en production.
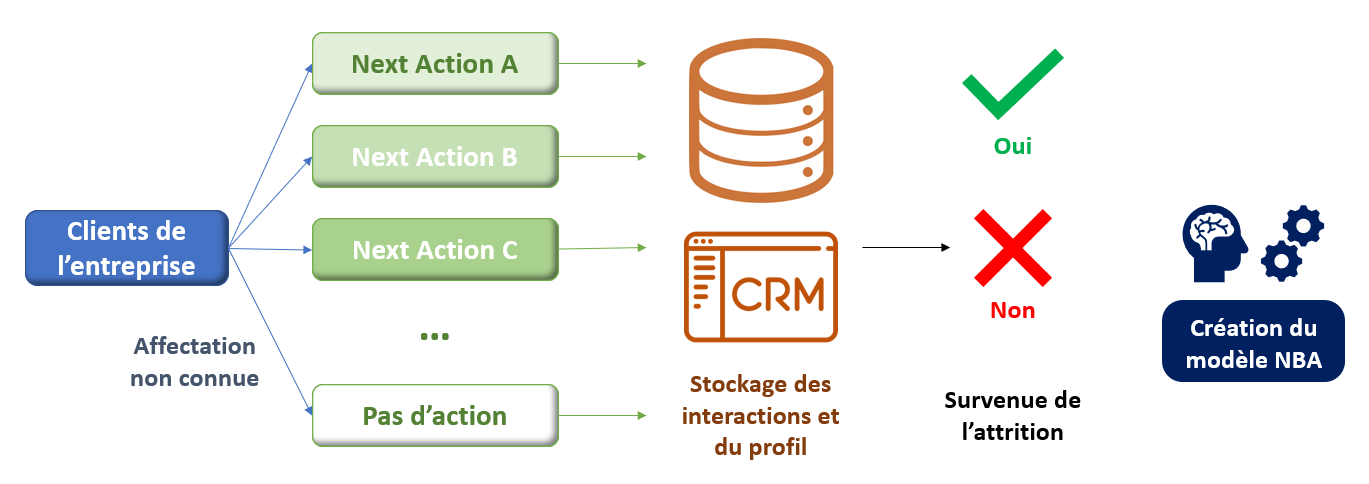
Schéma synthétique du projet NBA
Pour simplifier un peu le projet, nous choisissons de n’optimiser que la prochaine meilleure action pour chaque client, et non une potentielle suite d’actions à mener. Dans le cas des séquences d’actions, les méthodes de reinforcement learning sont plus adaptées, mais nécessitent des volumes de données plus conséquents.
Quelles sont les problématiques liées à ce projet ?
Grace à notre expertise AVISIA, nous proposons une solution avec 4 étapes principales :

Nous ne connaissons pas la méthode d’attribution des actions passées, donc nous ne pouvons pas utiliser de manière directe l’historique des actions et réponses associées. En effet, la quantification de l’influence d’une action sur un client suppose que toutes les caractéristiques du client soient fixées : on sépare de manière aléatoire tous nos clients en 2 (ou n) populations, et la seule variable qui change de manière certaine et déterministe est le fait de recevoir telle ou telle action (ou aucune). Dans ce cas, le caractère aléatoire de la sélection assure l’absence de biais et la relative simplicité du projet.
Dans notre cas, cela n’est pas possible ; il faut donc déterminer à quel point les 2 populations divergent (celle pour qui nous effectuons l’action A, et l’autre pour l’action B). Pour ce faire, 2 solutions :
Selon le résultat de la méthode employée, la correction du biais peut être effectuée selon 3 méthodes :
À AVISIA, nous recommandons l’utilisation de la dernière approche. En quelques mots (sinon l’article deviendrait un peu long…), il s’agit de rééchantillonner les 2 groupes ayant reçu l’action A ou l’action B en fonction d’un modèle qui cherche à estimer, en fonction de caractéristiques connues (et susceptibles d’influer sur l’action choisie), la probabilité que l’entreprise affecte l’action A (ou B) au client.
Dans le cadre d’une entreprise qui veut mettre en place plus de 2 actions personnalisées, il suffit de changer le score de propension d’un modèle binaire à un modèle multi-classes.
Une fois que les différentes populations associées aux actions ont été rééquilibrées, la prochaine étape est de déterminer, pour chaque client, son risque de churn. Ce type de modèle prédictif est très couramment utilisé, et nous intervenons depuis plusieurs années au sein d’AVISIA chez nos clients pour mettre en place de type de projets.
Afin d’améliorer l’efficacité de ce projet, nous proposons chez AVISIA d’aller au-delà du score de churn et d’employer la méthode du modèle d’uplift. Il s’agit, en plus de déterminer les clients à risque de churn qu’il faut essayer de faire revenir, quels sont les clients qui sont réceptifs à une communication ou une offre de la part de l’entreprise.
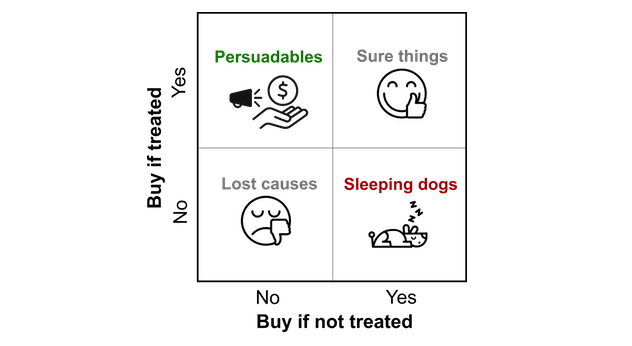
Schéma explicatif de l’uplift modeling dans le cadre de l’appétence
L’uplift cherche à distinguer, parmi les clients à risque de churn, ceux pour lesquels il n’est pas utile de mettre en place une NBA (les « Lost Causes » dans le schéma), parce qu’ils réaliseront leur churn quelle que soit l’action mise en place. À l’inverse, les « Persuadables » sont intéressants car ils peuvent redevenir clients / actifs si une action est mise en place, mais sont à risque de churn si ce n’est pas le cas. Enfin, les « Sleeping Dogs » sont une population qu’il est important de surveiller, car ce sont des personnes qui sont à risque de churn uniquement quand une action personnalisée leur est proposée (réticence à la personnalisation ou aux contacts).
De manière mathématique, l’uplift se calcule comme suit :
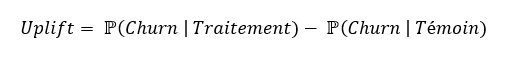 Définition de l’uplift
Définition de l’uplift
Un modèle d’uplift peut être mis en place selon 2 méthodes :
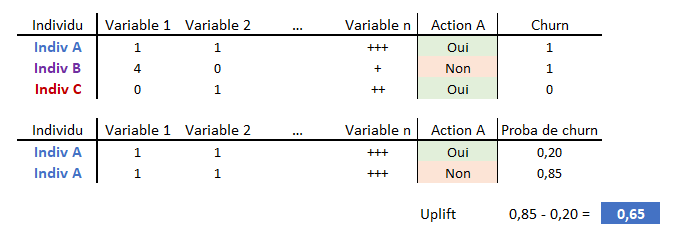
 Par calcul, en supposant que les échantillons Traitement et Témoin sont équirépartis, il est possible de montrer que l’uplift est proportionnel à la probabilité de prédire cette nouvelle cible comme étant égale à 1.
Par calcul, en supposant que les échantillons Traitement et Témoin sont équirépartis, il est possible de montrer que l’uplift est proportionnel à la probabilité de prédire cette nouvelle cible comme étant égale à 1.La meilleure action à employer pour un client s’obtient donc en estimant l’uplift associé à chaque action possible. Il est possible d’utiliser cette information en conjonction avec des règles métiers pour affiner la NBA, ainsi que des informations sur le client pour aider un conseiller clientèle à délivrer le bon discours associé.
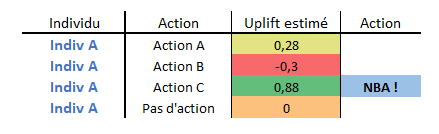
Choix de la NBA : l’action C est la meilleure pour le client A
Avant d’être prêt pour la production et la mise en place d’A/B tests sur les actions, le modèle NBA doit être évalué sur l’historique des données. Il existe plusieurs méthodes :
Il s’agit d’évaluer la performance du modèle pour chaque action mise en place : le niveau de churn des individus du groupe Traitement (action mise en place) est comparé au niveau de churn des individus du groupe Témoin :
Les uplift réel et prédit doivent être cohérents entre eux pour les différentes actions possibles.
Comme pour calculer un graphique de lift dans une problématique de scoring classique, les individus sont classés par déciles croissants d’uplift prédit. Dans chaque décile, nous disposons à la fois d’individus ayant churné et non churné et appartenant au groupe Traitement et Témoin. Il est donc possible d’estimer la différence des taux de churn pour les groupes Traitement et Témoin dans chaque décile, et donc l’uplift réel.
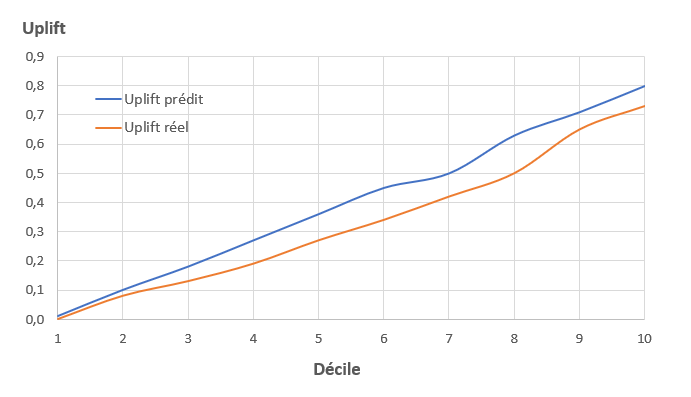 Vérification de l’uplift par la méthode de déciles
Vérification de l’uplift par la méthode de déciles
Pour déterminer la NBA, nous estimons l’uplift pour toutes les actions afin de déterminer la meilleure. Grâce à l’historique des actions mises en place dans l’entreprise, nous savons quelle action a été mise en place. Nous pouvons donc calculer l’uplift réel pour ces actions. Le modèle NBA est donc performant si l’uplift prédit est meilleur que l’uplift réel.
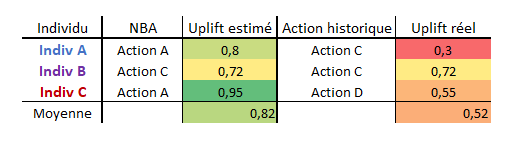 Exemple de validation par la comparaison des uplift
Exemple de validation par la comparaison des uplift
Nous avons décrit les principales étapes d’un projet complet de prédiction de la prochaine meilleure action à proposer à un client pour éviter son attrition. Les étapes décrites présentent parfois plusieurs méthodes possibles, qui possèdent chacune leurs avantages et inconvénients en termes de complexité, simplicité et performance. Dans tous les cas, même avec des méthodes simples et peu de ressources marketing, il est possible d’établir un modèle NBA. Son amélioration nécessite tout de même de maîtriser les méthodes et leur théorie sous-jacente, et donc de choisir parmi elles.




 (1600 x 760 px) (1920 x 1080 px)-2")













Data contact


